Klasyczna Metoda Najmniejszych Kwadratów (KMNK), znana również jako Ordinary Least Squares (OLS), to podstawowa technika w ekonometrii. Służy do szacowania parametrów w modelach regresji liniowej. Postaramy się zrozumieć jej działanie krok po kroku.
Zacznijmy od definicji modelu regresji liniowej. Jest to równanie, które zakłada liniową zależność między zmienną zależną a jedną lub wieloma zmiennymi niezależnymi (objaśniającymi). Mówiąc prościej, chcemy znaleźć linię, która najlepiej opisuje związek między danymi.
Podstawy Metody Najmniejszych Kwadratów
Załóżmy, że mamy prosty model regresji liniowej: Y = β₀ + β₁X + ε. Gdzie Y to zmienna zależna, X to zmienna niezależna, β₀ to wyraz wolny (punkt przecięcia z osią Y), β₁ to współczynnik kierunkowy (nachylenie linii), a ε to składnik losowy (błąd).
Celem KMNK jest znalezienie takich wartości β₀ i β₁, które minimalizują sumę kwadratów różnic między obserwowanymi wartościami Y a wartościami przewidywanymi przez model. To właśnie stąd pochodzi nazwa "najmniejszych kwadratów".
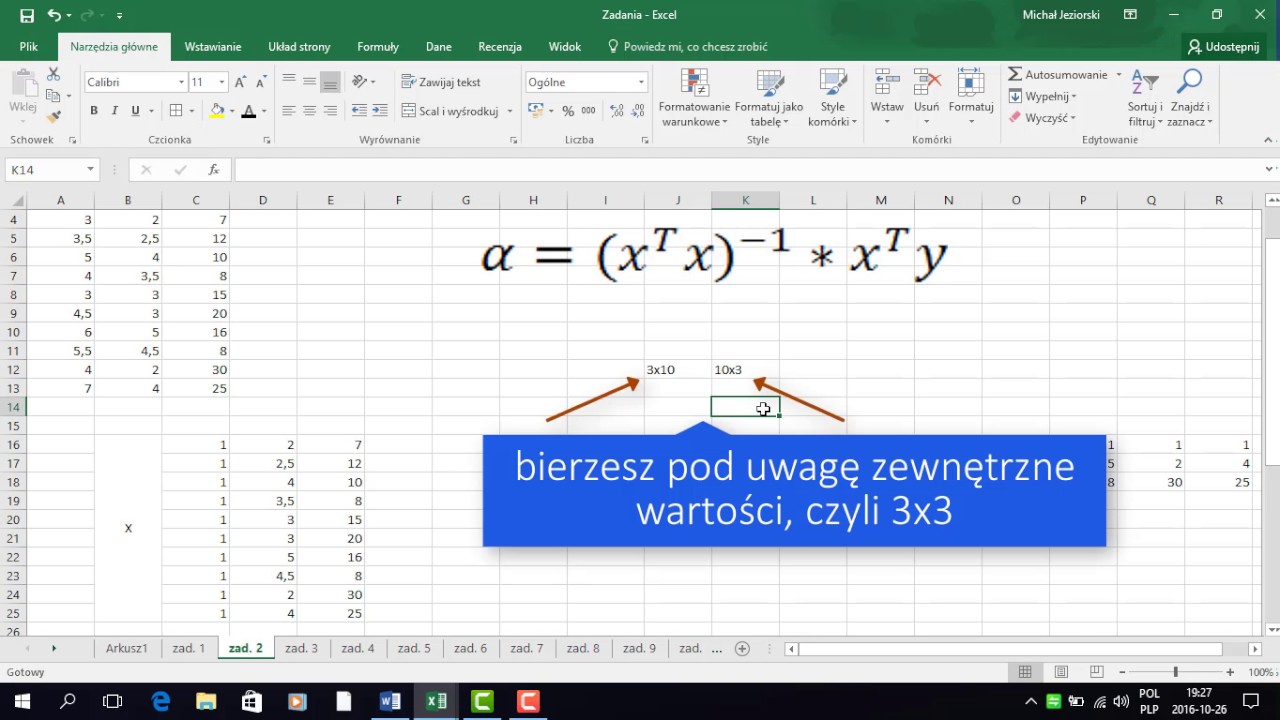
Formalnie, minimalizujemy funkcję: ∑(Yᵢ - Ŷᵢ)², gdzie Yᵢ to obserwowana wartość zmiennej zależnej dla obserwacji i, a Ŷᵢ to wartość przewidywana przez model dla tej samej obserwacji. Ŷᵢ możemy zapisać jako β₀ + β₁Xᵢ.
Proces Minimalizacji
Aby znaleźć wartości β₀ i β₁, które minimalizują sumę kwadratów reszt, stosujemy rachunek różniczkowy. Obliczamy pochodne cząstkowe funkcji błędu względem β₀ i β₁, a następnie przyrównujemy je do zera. Rozwiązanie układu równań pozwala nam wyznaczyć estymatory KMNK dla β₀ i β₁.
Otrzymujemy wzory na estymatory: β₁̂ = Cov(X, Y) / Var(X) oraz β₀̂ = Ȳ - β₁̂X̄. Gdzie Cov(X, Y) to kowariancja między X i Y, Var(X) to wariancja X, Ȳ to średnia z Y, a X̄ to średnia z X.
Te wzory pozwalają nam obliczyć estymowane wartości współczynników regresji na podstawie danych. Wyestymowane wartości oznaczamy kapeluszem, np. β₁̂.
Założenia Klasycznej Metody Najmniejszych Kwadratów
Aby estymatory KMNK były nieobciążone (czyli średnio równe prawdziwym wartościom) i najefektywniejsze (czyli miały najmniejszą wariancję spośród estymatorów liniowych nieobciążonych), muszą być spełnione pewne założenia. Nazywamy je założeniami klasycznego modelu regresji liniowej (KMR).
1. Liniowość modelu: Zakładamy, że zależność między zmienną zależną a zmiennymi niezależnymi jest liniowa. To znaczy, że model jest poprawnie specyfikowany jako liniowy.
2. Brak endogeniczności: Zmienne niezależne nie są skorelowane ze składnikiem losowym. Oznacza to, że nie ma zmiennych pominiętych w modelu, które wpływają zarówno na Y, jak i na X.
3. Brak autokorelacji składnika losowego: Składniki losowe dla różnych obserwacji są nieskorelowane ze sobą. Oznacza to, że błąd dla jednej obserwacji nie wpływa na błąd dla innej obserwacji.
4. Homoskedastyczność: Wariancja składnika losowego jest stała dla wszystkich obserwacji. Oznacza to, że rozrzut błędu jest taki sam dla wszystkich wartości X.
5. Brak współliniowości: Zmienne niezależne nie są ze sobą idealnie skorelowane. Silna współliniowość może utrudniać interpretację wyników i prowadzić do dużych wariancji estymatorów.
6. Składnik losowy ma rozkład normalny: Ten warunek jest potrzebny do przeprowadzenia testów statystycznych i budowy przedziałów ufności.
Interpretacja Wyników
Po wyestymowaniu modelu regresji liniowej możemy interpretować uzyskane współczynniki. Na przykład, jeśli β₁̂ = 2, to oznacza, że wzrost X o jednostkę powoduje średni wzrost Y o 2 jednostki, przy założeniu, że inne zmienne są stałe.
Wartość β₀̂ interpretujemy jako wartość Y, gdy X wynosi 0. Ważne jest, aby sprawdzić, czy taka interpretacja ma sens w kontekście analizowanego problemu.
Możemy również ocenić, jak dobrze model dopasowuje się do danych za pomocą współczynnika determinacji R². R² informuje, jaka część zmienności zmiennej zależnej jest wyjaśniana przez zmienne niezależne w modelu. Wartości R² bliskie 1 oznaczają dobre dopasowanie.
Przykład Praktyczny
Załóżmy, że chcemy zbadać wpływ wydatków na reklamę (X) na sprzedaż (Y). Zbieramy dane dotyczące wydatków na reklamę i sprzedaży dla różnych firm.
Następnie stosujemy KMNK do wyestymowania parametrów modelu: Sprzedaż = β₀ + β₁ * WydatkiNaReklamę + ε. Otrzymujemy wyniki: β₀̂ = 100 i β₁̂ = 5.
Interpretacja: Jeśli wydatki na reklamę wzrosną o 1 jednostkę, to sprzedaż średnio wzrośnie o 5 jednostek, przy założeniu, że inne czynniki pozostają bez zmian. Sprzedaż wynosi 100, gdy wydatki na reklamę wynoszą 0.
Zastosowania Ekonometrii
KMNK jest szeroko stosowana w różnych dziedzinach ekonomii i ekonometrii. Może być używana do prognozowania, analizy polityki gospodarczej, badania efektów interwencji, oceny skuteczności programów społecznych i wielu innych celów.
Przykładowe zastosowania to: analiza wpływu stóp procentowych na inflację, badania wpływu edukacji na zarobki, prognozowanie PKB, analiza popytu i podaży, ocena wpływu podatków na zachowania konsumentów.
Pamiętajmy, że KMNK to potężne narzędzie, ale należy stosować je z rozwagą i zawsze sprawdzać spełnienie założeń modelu. W przeciwnym razie wyniki mogą być błędne i prowadzić do nieprawidłowych wniosków.