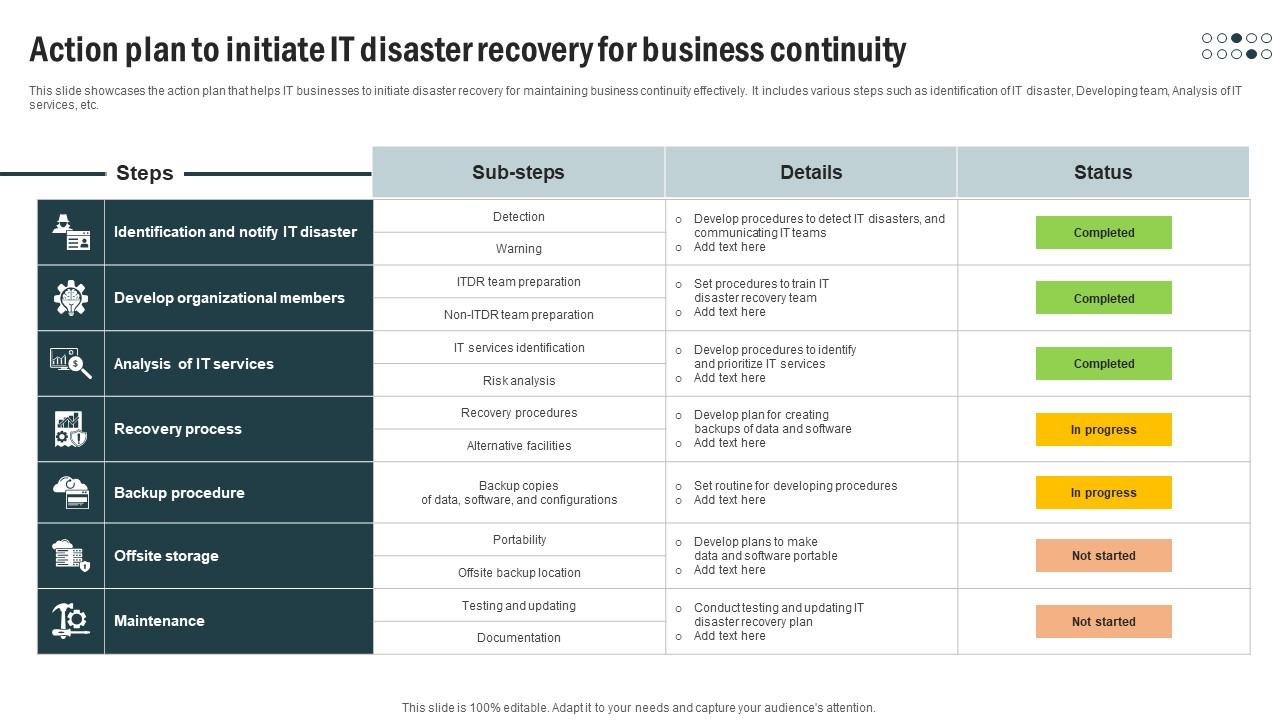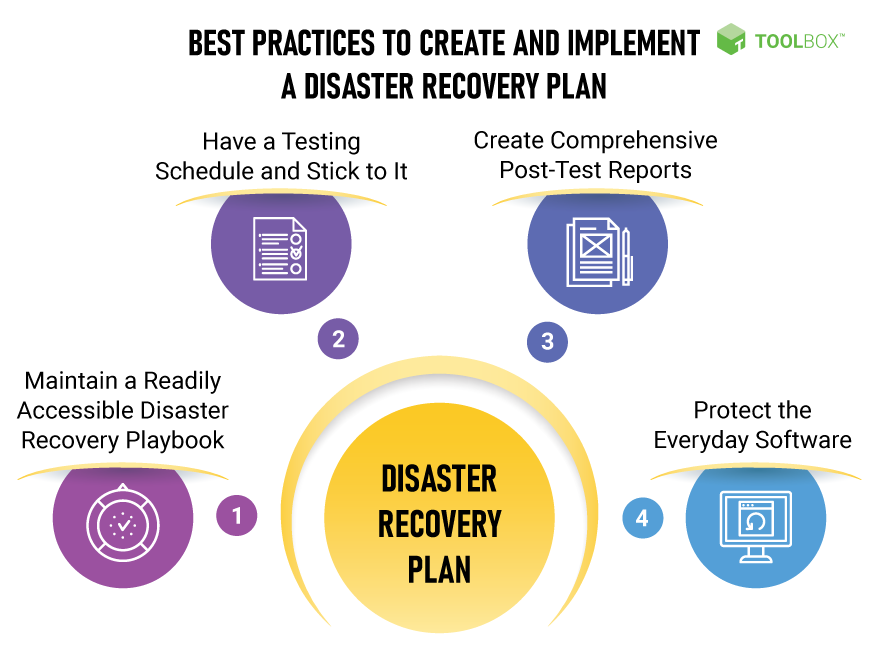
Hej! Przygotowujesz się do egzaminu z zakresu Disaster Recovery? Świetnie! Razem to ogarniemy. Skupimy się na praktykach, które mogą inicjować proces odzyskiwania po awarii. Zaczynamy!
Monitorowanie i Alertowanie
Monitorowanie to kluczowa sprawa. Ciągłe sprawdzanie stanu systemów i infrastruktury.
Co monitorujemy? Wydajność serwerów, sieć, aplikacje i bazy danych.
Jeśli coś odbiega od normy, uruchamiają się alerty. To one mogą zainicjować Disaster Recovery.
Przykłady Alertów Inicjujących DR
Awaria serwera. Całkowite zatrzymanie działania serwera.
Przeciążenie sieci. Nagły wzrost ruchu sieciowego.
Uszkodzenie bazy danych. Korupcja danych lub niedostępność.
Atak ransomware. Zaszyfrowanie danych przez złośliwe oprogramowanie.
Alert to sygnał, że coś złego się dzieje. Wymaga szybkiej reakcji.
Testowanie Odzyskiwania Po Awarii (DR)
Testowanie DR to symulacja awarii. Sprawdzamy, czy plan odzyskiwania działa.
Testy mogą ujawnić problemy, które uruchomią prawdziwe Disaster Recovery.
Scenariusze Testowe
Test failover. Przełączenie na zapasowe systemy.
Test przywracania danych. Odtworzenie danych z kopii zapasowych.
Test aplikacji. Uruchomienie aplikacji w środowisku zapasowym.
Jeśli test ujawni błędy, konieczne może być uruchomienie DR w celu naprawy.
Testy są bardzo ważne. Pozwalają uniknąć problemów w prawdziwej awarii.
Audyty Bezpieczeństwa
Audyty bezpieczeństwa oceniają poziom zabezpieczeń systemów.
Wykrywają luki, które mogą prowadzić do awarii i konieczności DR.
Obszary Audytu
Zabezpieczenia sieci. Firewalle, systemy wykrywania włamań.
Zarządzanie tożsamością i dostępem. Kontrola dostępu do systemów.
Ochrona danych. Szyfrowanie, kopie zapasowe.
Jeśli audyt wykryje poważne zagrożenia, trzeba działać. Inicjacja DR może być konieczna, aby zabezpieczyć dane.
Audyty to inwestycja w bezpieczeństwo. Pomagają zapobiegać awariom.
Zarządzanie Zmianami
Zarządzanie zmianami kontroluje wprowadzanie zmian w systemach.
Nieprawidłowe zmiany mogą spowodować awarie i uruchomić DR.
Proces Zarządzania Zmianami
Wniosek o zmianę. Opis zmiany i jej wpływu.
Ocena ryzyka. Identyfikacja potencjalnych problemów.
Testowanie zmiany. Sprawdzenie, czy zmiana działa poprawnie.
Wdrożenie zmiany. Wprowadzenie zmiany do systemu.
Jeśli zmiana spowoduje awarię, trzeba ją wycofać. Disaster Recovery może być potrzebne, aby przywrócić system do stanu sprzed zmiany.
Dobre zarządzanie zmianami minimalizuje ryzyko awarii.
Reagowanie na Incydenty
Reagowanie na incydenty to proces radzenia sobie z problemami bezpieczeństwa.
Poważny incydent może wymagać uruchomienia DR.
Przykłady Incydentów
Atak DDoS. Zablokowanie dostępu do serwera.
Wyciek danych. Utrata poufnych informacji.
Wirus. Zainfekowanie systemów złośliwym oprogramowaniem.
Reagowanie na incydent obejmuje identyfikację, powstrzymanie i usunięcie zagrożenia. Czasami wymaga to inicjacji DR.
Szybka reakcja na incydenty minimalizuje straty.
Podsumowanie
Zapamiętaj! Monitorowanie i alertowanie, testowanie DR, audyty bezpieczeństwa, zarządzanie zmianami i reagowanie na incydenty to praktyki, które mogą prowadzić do inicjacji Disaster Recovery.
Każda z tych praktyk ma na celu wykrycie lub zapobieżenie awarii. Jeśli jednak awaria nastąpi, DR jest ostatnią deską ratunku.
Pamiętaj, regularne testowanie i aktualizacja planu DR są kluczowe! Powodzenia na egzaminie!