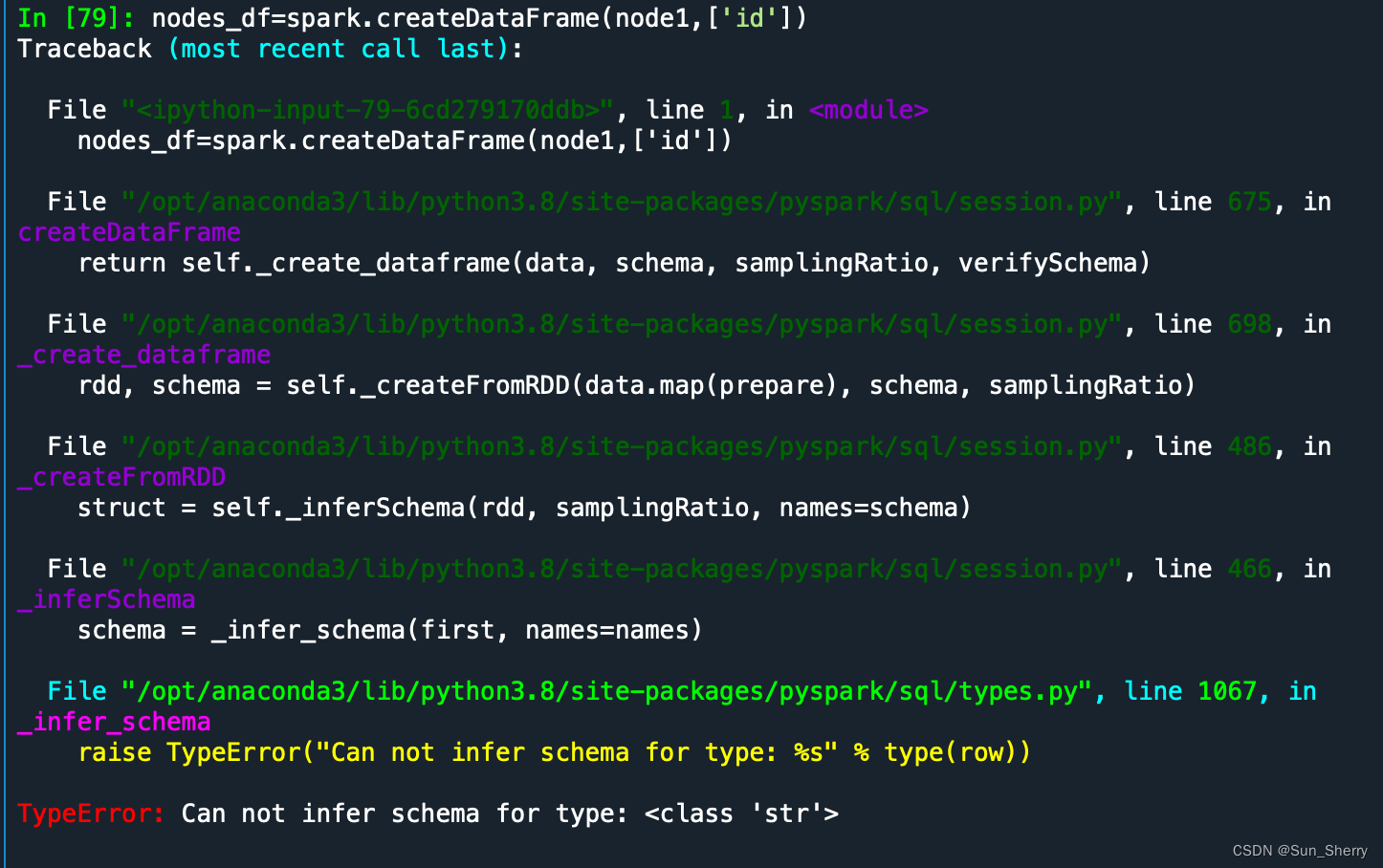
Często podczas pracy z danymi, szczególnie w językach programowania takich jak Spark czy Pandas (w Pythonie), spotykamy się z komunikatem błędu: "Can Not Infer Schema For Type Class Str". Rozumiemy go jako problem z automatycznym rozpoznaniem struktury danych typu łańcuchowego (String). Wynika to z tego, że system nie potrafi sam określić, jak interpretować kolumnę tekstową.
Co to jest Schema?
Schema, czyli schemat, to nic innego jak struktura danych. Określa typ danych każdej kolumny w tabeli lub ramce danych. Na przykład, kolumna może zawierać liczby całkowite (Integer), liczby zmiennoprzecinkowe (Float), daty (Date), wartości logiczne (Boolean), czy właśnie łańcuchy znaków (String). Schemat umożliwia systemowi poprawne odczytywanie, przetwarzanie i analizowanie danych.
Bez zdefiniowanego schematu, system nie wie, jak traktować poszczególne wartości. Czy kolumna tekstowa powinna być traktowana jako zwykły tekst? A może jako reprezentacja liczb, dat lub innych bardziej złożonych struktur? Brak schematu prowadzi do błędów i nieprawidłowych wyników.
Dlaczego Schema Nie Może Być Automatycznie Wywnioskowana dla String?
Problem z automatycznym wnioskowaniem schematu dla typu String wynika z samej natury tekstu. Tekst może reprezentować praktycznie wszystko. Może to być imię, nazwisko, adres, opis produktu, kod pocztowy, a nawet zakodowane dane.
System nie jest w stanie samodzielnie zdecydować, który z tych przypadków jest właściwy. Dlatego, w wielu sytuacjach, wymaga od nas, programistów, jawnego zdefiniowania schematu. Jest to szczególnie ważne, gdy dane tekstowe mają specyficzną strukturę lub reprezentują inne typy danych.
Przykłady Sytuacji, Gdzie Występuje Błąd
Wyobraźmy sobie, że mamy plik CSV z danymi o produktach. Jedna z kolumn nazywa się "KodProduktu" i zawiera unikalne identyfikatory produktów. System próbuje automatycznie odczytać ten plik, ale nie potrafi poprawnie zinterpretować kolumny "KodProduktu", ponieważ składa się ona z ciągu znaków.
Inny przykład to odczyt danych z bazy danych. Kolumna "Opis" zawiera długie opisy produktów. System również może mieć problem z wywnioskowaniem schematu dla tej kolumny, szczególnie jeśli opisy są bardzo zróżnicowane i zawierają różne formaty.
Jak Rozwiązać Problem?
Najprostszym rozwiązaniem jest jawne zdefiniowanie schematu. W Sparku możemy to zrobić za pomocą klasy StructType i StructField. Określamy nazwę każdej kolumny i jej typ danych. Dla kolumn tekstowych używamy typu StringType.
W Pandas (w Pythonie) możemy zdefiniować typ danych dla kolumn podczas odczytu pliku CSV za pomocą parametru `dtype` funkcji `read_csv()`. Możemy również zmienić typ kolumny po odczytaniu danych za pomocą metody `astype()`. Na przykład, `df['KodProduktu'] = df['KodProduktu'].astype(str)` zamieni kolumnę 'KodProduktu' na typ string.
Czasami, problem może leżeć w nieprawidłowym formacie danych. Na przykład, kolumna, która powinna zawierać liczby, zawiera puste wartości lub znaki specjalne. W takim przypadku, musimy najpierw oczyścić dane, usuwając nieprawidłowe wartości lub zamieniając je na wartości domyślne.
Pamiętajmy, że precyzyjne zdefiniowanie schematu jest kluczowe dla poprawnego przetwarzania danych. Pomaga uniknąć błędów, poprawia wydajność i umożliwia wykorzystanie pełnego potencjału narzędzi do analizy danych.
Przykładowy Kod w Spark
Załóżmy, że mamy ramkę danych (DataFrame) o nazwie `df`. Chcemy zdefiniować schemat dla kolumny o nazwie "NazwaProduktu". Poniżej znajduje się przykładowy kod:
from pyspark.sql.types import StructType, StructField, StringType
schema = StructType([
StructField("NazwaProduktu", StringType(), True)
])
# Zakładając, że 'data' to lista krotek z danymi
df = spark.createDataFrame(data, schema=schema)
W tym przykładzie, tworzymy obiekt StructType, który definiuje schemat. StructField określa nazwę kolumny ("NazwaProduktu"), typ danych (StringType) i czy kolumna może zawierać wartości null (True oznacza, że tak). Następnie używamy tego schematu podczas tworzenia ramki danych.
Podsumowanie
Błąd "Can Not Infer Schema For Type Class Str" informuje nas o problemie z automatycznym rozpoznaniem schematu dla kolumn tekstowych. Rozwiązaniem jest jawne zdefiniowanie schematu, czyszczenie danych lub analiza przyczyn problemów z rozpoznaniem formatu danych. Określenie schematu zapobiega błędom i pozwala na efektywne przetwarzanie i analizę danych.